Одним із важливих етапів SEO просування є збір семантичного ядра. Семантика складається з ключових слів, за якими потім просувають сайт і з якими seo-спеціаліст працює. Наприклад, тільки після збору семантичного ядра та його кластеризації можна створити правильну структуру сайту. Та врахуйте, що для сайтів певних тематик слід задіювати й фактори EEAT SEO, тож там роботи буде більше.
Вивантажити семантичне ядро можна за допомогою різних сервісів, таких як Serpstat або Ahrefs. Але дуже часто виникає проблема з тим, як прискорити кластеризацію ключових слів, і як правильно це зробити.
Наведу 3 покрокових способи, як зробити кластеризацію семантичного ядра.
Кластеризація семантичного ядра — це розподіл ключових слів на групи, які мають логічну схожість один з одним і закривають однакові потреби користувача при пошуку в пошуковій системі.
За допомогою кластеризації можна ефективно розподілити ключові слова на сторінках або категоріях, і на основі цих груп складати стратегії просування та відстежувати важливі SEO метрики розвитку сайту.
Існує кілька варіантів кластеризації:
Тому, як на мене, найзручніший варіант – це змішаний. Нижче наведу кілька прикладів, як це можна зробити.
Далі наведу 3 способи кластеризації семантики у Google таблицях:
Почнемо.
Запити (Queries) – це функція в Google Таблицях, що дозволяє працювати з даними у таблиці за допомогою спеціальної мови запитів.
Мова запитів у Google Таблицях базується на SQL (Structured Query Language), яка є стандартною мовою для роботи з базами даних. Однак SQL набагато простіший і орієнтований на роботу з таблицями. Більш детально можна ознайомитись у довідці Google.
Для того, щоб кластеризувати семантику, я використовую наступний запит: =QUERY(діапазон осередків; “SELECT * WHERE A CONTAINS ‘будь-яке слово’”)

Рис. 1 – Вивантаження семантичного ядра
Після додавання цієї функції всі ключові слова, які містять потрібне слово, будуть автоматично перенесені до кластера. Приклад, як це спрацювало, наведено на скриншоті.

Рис. 2 – Додавання формули до черги
Розберемо мій запит докладніше: =QUERY(‘Семантика Oribe’!A2:B862; “SELECT * WHERE A CONTAINS ‘шампун’”)
‘Семантика Oribe’!A2:B862 – в діапазоні, де відбувається пошук потрібного слова, я написала Лист, на якому потрібно шукати та діапазон осередків. У моєму випадку це був лист Семантика Oribe. Ці значення слід замінювати.
SELECT * WHERE A CONTAINS – цей вираз означає, що потрібно вибрати всі слова, які містять певне слово. У цьому випадку я додала слово “шампун” без закінчення, щоб цей запит витягнув слова з різними варіантами закінчень.
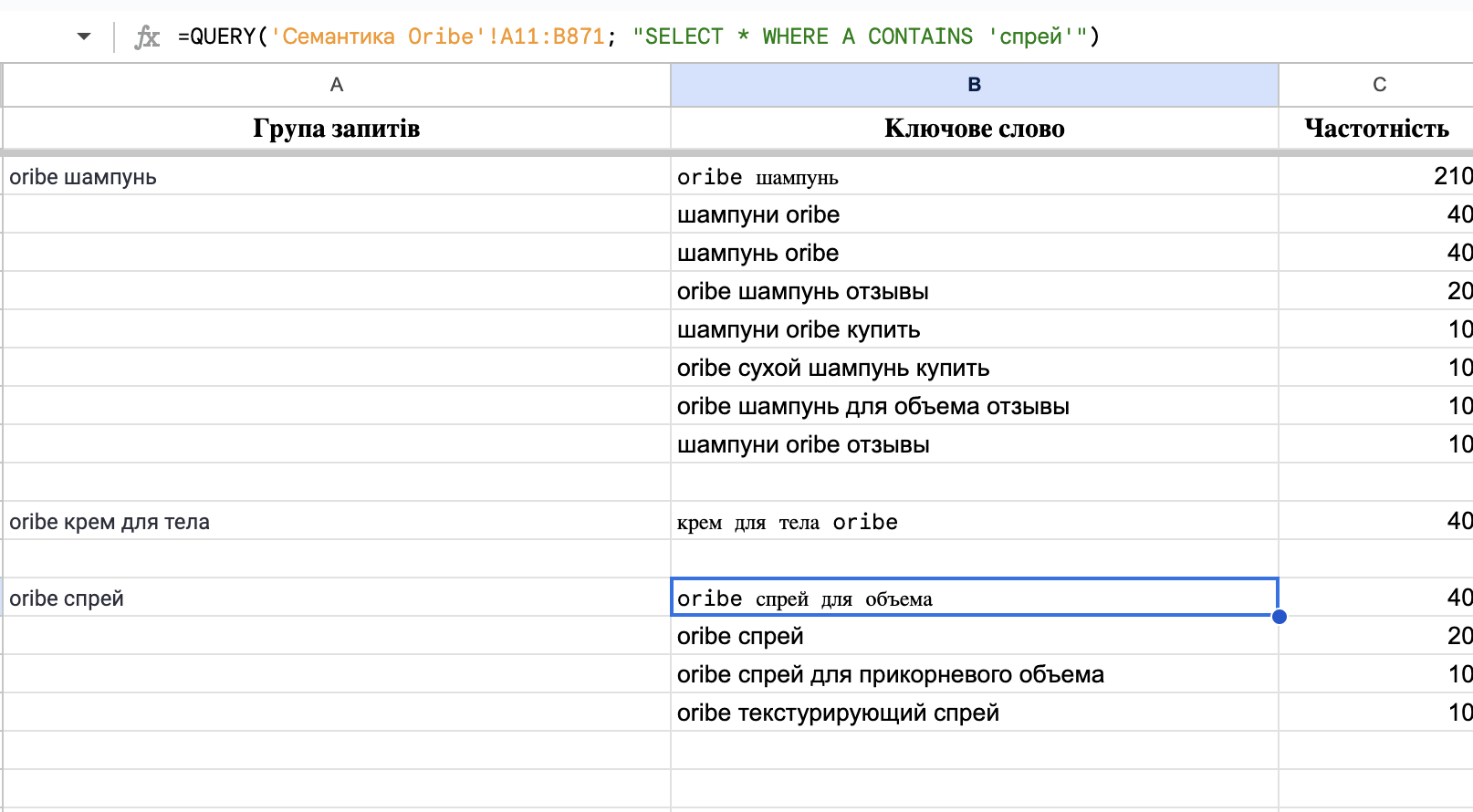
Рис. 3 – Застосування формули до інших запитів
Перевага цього методу полягає в тому, що ви отримуєте відразу готові групи запитів, які можна трохи почистити руками, і кластери готові.
За бажанням цей запит можна доробити під різні варіанти. Мені зручніше було так використовувати, тому що я перевіряю всю семантику, яку витягую за запитами, а потім чищу знайдене.
Синтаксис та правила мови запитів є в офіційній довідці Google.
За допомогою цієї формули можна вибрати потрібні ключові слова з певним словом. Але доведеться самостійно копіювати ключі та переносити їх у кластери.
Наприклад, взяла цю ж семантику. На аркуш із семантикою в стовпець С я додам формулу для пошуку всіх ключових слів із входженням слова шампунь: =FIND(“шампун”; A2; 1).
Далі мені потрібно цю формулу поставити в стовпці С до комірки С101, щоб охопити всі дані. Якщо потрібно витягнути всі варіанти зі словом шампунь, краще писати слово без закінчення. Докладніше на скриншоті.

Рис. 4 – Кластеризація запитів за допомогою формули
Для того, щоб автоматично проставити формулу по всьому стовпцю С до закінчення заповнених осередків:
Формула працює таким чином, що якщо вона знаходить у рядку ключове слово із входженням слова Шампунь, то вона залишає там будь-яку цифру. Далі потрібно зробити сортування від А до Я, як показано на скриншоті. Тоді всі ключові слова зі словом шампунь будуть відсортовані нагору. Потім потрібно їх скопіювати та почистити, і перенести на лист з кластерами.

Рис. 5 – Сортування запитів
Результат відсортованих ключів наведено на скриншоті нижче:

Рис. 6 – Результат сортування
Результат виходить такий само, як і при використанні функції запитів. Тому різниці в якості немає. Але цей метод не переносить одразу ключові слова, їх потрібно копіювати та вставляти. А плюс цього методу в тому, що можна розібрати все семантичне ядро і нічого не проґавити, тому що перенесені ключові слова можна видалити та кластеризувати інші. І в такий спосіб перебрати всі варіанти.
Мені цей метод допоміг, коли мені потрібно було створити якнайбільше посадкових сторінок для сайту.
Ще один і найпростіший спосіб кластеризації – це просто використовувати фільтри. Виділяємо комірки та створюємо фільтр. Вибираємо фільтр за умовою.

Рис. 7 – Кластеризація за допомогою фільтра
Далі вибираємо Текст містить та вставляємо потрібне слово для кластера. Я знову роблю кластер для шампунів від бренду. Потім натискаємо ОК і з’являються всі запити зі словом шампунь.
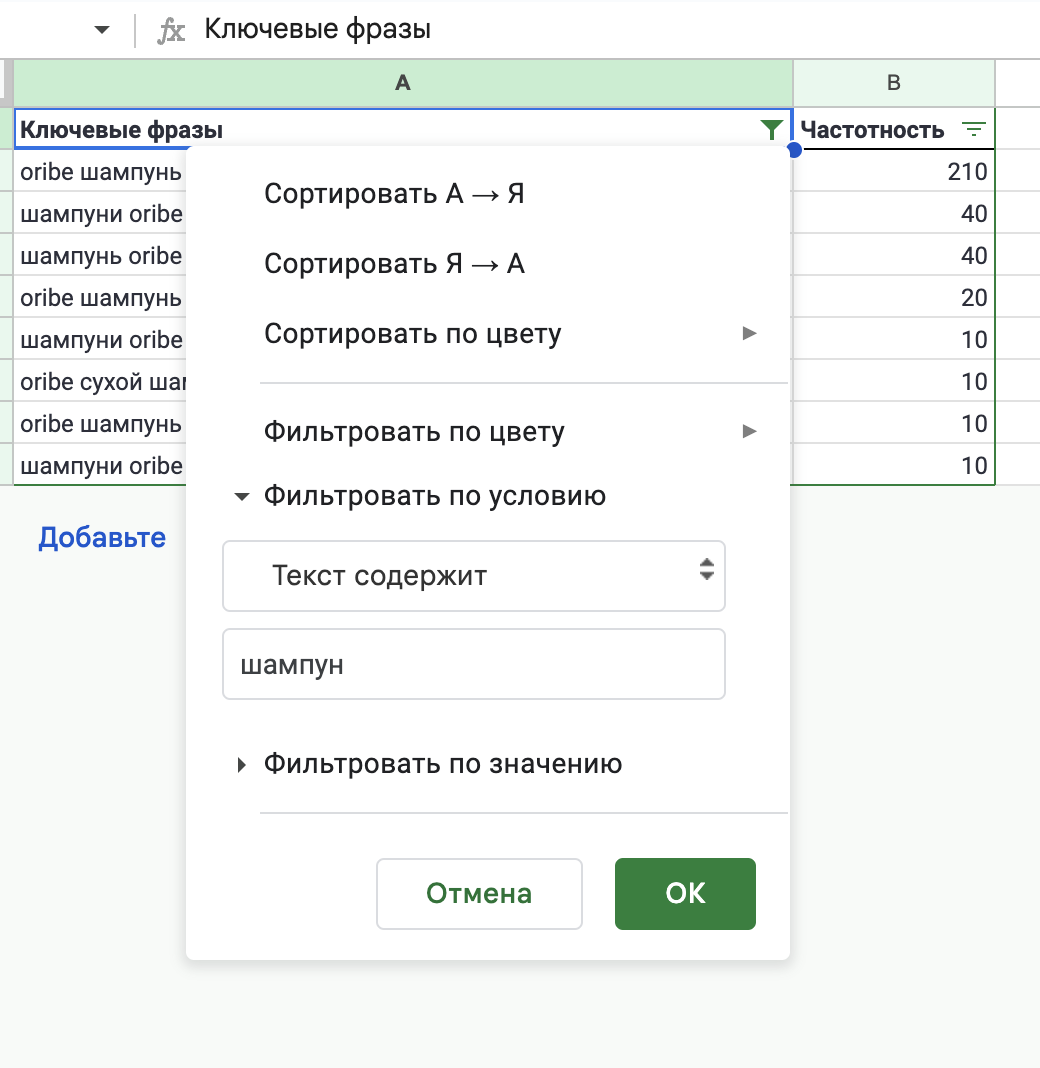
Рис. 8 – Кластеризація для запитів шампунь
Результат на скриншоті:

Рис. 9 – Результат кластеризації за фільтром
Результат такий самий, але цей спосіб також передбачає самостійне перенесення цих ключів. Плюс — у швидкому чищенні та відсутності пропуску ключових слів. Найголовніше, щоб усі ключові слова були відзначені, інакше вони не будуть показані.
Семантичне ядро можна кластеризувати автоматично за допомогою сервісів. Є багато різних сервісів. Але в цій статті я покажу, як кластеризація працює від Serpstat. Раніше мені зовсім не подобалося, як працювала дана кластеризація, доводилося вносити багато правок вручну. Але останнім часом кластеризація саме від цього сервісу працює досить непогано.
Заходимо до звіту Кластеризація Текстова аналітика та створюємо новий проєкт. Я вирішила протестувати, як цю семантику може кластеризувати цей сервіс. Заповнила поля та обрала тип зв’язку сильний, а тип кластеризації – жорсткий. Це допоможе мені зробити точніші групи запитів бренд + тип косметики.
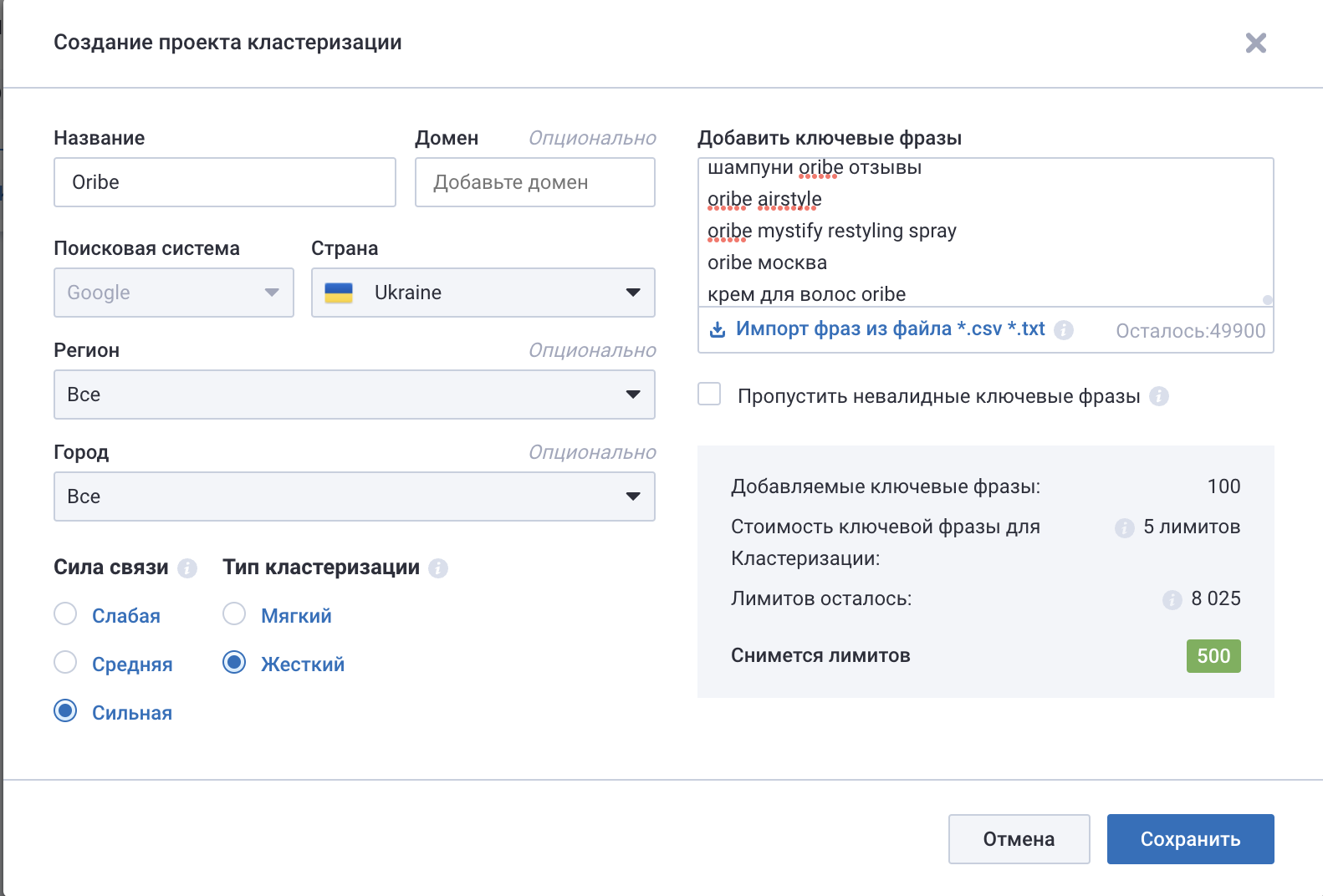
Рис. 10 – Кластеризація за допомогою serpstat
Заповнивши ключові слова та натиснувши Зберегти, потрібно трохи почекати, поки сервіс кластеризує семантику. Тепер знову повернемося до шампунів і подивимося, який кластер ми отримали.
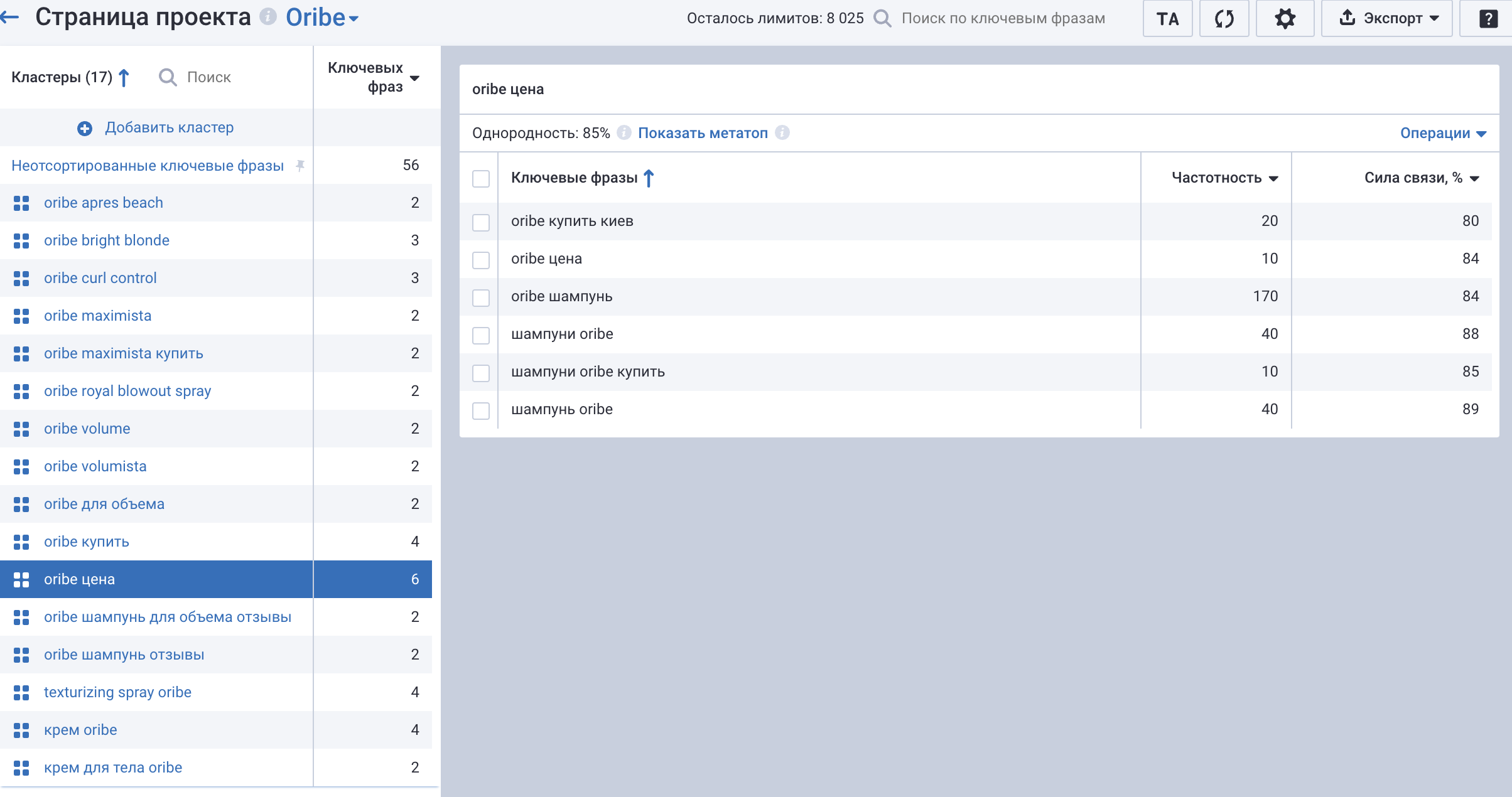
Рис. 11 – Результат кластеризації у serpstat
При жорсткому зв’язку окремої групи для шампунів Serpstat не зробив, але додав запити з шампунями до групи запитів oribe ціна. Натомість було створено групу запитів із шампунями для обсягу. На жаль, зі 100 ключових слів 56 потрапили до групи невідсортовані, тож їх все одно доведеться переглядати та правити ручками.
Після цього я тестувала м’який тип кластеризації, але звіт вийшов таким же, як і за жорсткої. Таким чином, все одно потрібно вручну переробляти кластери, тому що поточні не повністю влаштовують мене.
Для прикладів кластеризації було обрано нечищене семантичне ядро, тому запити там могли траплятися по-різному.
Усі методи та способи кластеризації по своєму непогані. Думаю, важливо підбирати спосіб під певний випадок. Навіть якщо ви вибираєте повністю автоматичну кластеризацію запитів, що значно прискорює роботу, то завжди перевіряйте кластери.
Мій же улюблений метод — це запити + фільтри в таблицях google. Це допомагає переглядати семантику та одразу чистити непотрібні запити.





