
В статье я покажу вам, как с помощью Screaming Frog извлекать данные:
И многого другого с применением XPath и регулярных выражений. Работать будем с реальными сайтами.
Screaming Frog по умолчанию собирает много важной информации:
Но что, если вы хотите использовать другие точки данных при сканировании вашего сайта?
С помощью Custom Extraction можно запрограммировать Screaming Frog для извлечения практически любой нужной вам информации. Как только вы поймете, как его использовать, сможете проводить более сложные обходы и анализ сайтов.
Вот несколько способов использования Custom Extraction для разработки идей и рекомендаций для SEO-стратегий наших клиентов:
Доступ к функции Custom Extraction получаем в раскрывающемся списке Configuration в разделе Custom > Extraction.

Рис. 1 – Раздел Configuration
Затем настраиваем правила извлечения. Инструкция поможет вам с этим.

Рис. 2 – Окно настройки правил извлечения
При запуске сканирования с использованием настраиваемого извлечения можно переключаться между параметрами фильтра извлечения, чтобы прийти к желаемому формату для ваших данных. Так некоторые из примеров из этого руководства требуют выбора определенного фильтра экстракции.
Данные, которые мы извлекаем, доступны на вкладке Custom. В раскрывающемся списке Filter выбираем Extraction.

Рис. 3 – Извлекаемые данные
Также он также в виде столбца на вкладке Internal рядом со всеми полями по умолчанию, которые заполняет Screaming Frog.
Что такое XPath?
Полное название термина – XML Path Language. XPath применяется для навигации по элементам и атрибутам в XML-документе.
XPath используется для извлечения любого HTML-элемента веб-страницы. Это могут быть:
В Google Chrome есть функция, которая упрощает написание XPath. Используя инструмент Inspect (посмотреть код), кликните правой кнопкой мыши любой элемент и скопируйте синтаксис XPath.

Рис. 4 – Контекстное меню для копирования XPath-запросов
Часто бывает так, что нужно изменить то, что предоставляет Chrome, прежде чем вставлять XPath в Screaming Frog. Inspect по крайней мере поможет разобраться в синтаксисе.
Основной синтаксис для парсинга XPath:
| Синтаксис | Функция |
| // | Искать в любом месте документа |
| / | Искать в корне |
| @ | Выберите определенный атрибут элемента |
| * | Подстановочный знак, используемый для выбора любого элемента |
| [] | Найдите конкретный элемент |
| . | Определяет текущий элемент |
| .. | Определяет родительский элемент |
Общие функции XPath:
| Оператор | Что делает |
| starts-with(x,y) | Проверяет, начинается ли x с y |
| contains(x,y) | Проверяет, содержит ли x y |
| last() | Находит последний предмет в наборе |
| count(XPath) | Подсчитывает количество случаев извлечения XPath |
Ниже в таблицах привожу примеры извлечения определенных элементов сайта. Вы можете скопировать синтаксис из столбца XPath и вставить его в Screaming Frog. Чтобы настроить извлечение в соответствии со своими потребностями, измените синтаксис по своему усмотрению.
| XPath | Что извлекает? |
| //h1 | Извлекает все теги H1 |
| //h3[1] | Извлечение первого тега H3 (в квадратных скобках указывается номер элемента) |
| //div/p | Любой тег <p> содержащийся в <div> |
| //div[@class=”] | Элементы в тегах <div> с определенным классом, указанным в кавычках |
| //*[@class=”] | Любые элементы в определенном классе |
| //ul/li[last()] | Последние элементы в маркированных списках <li> <ul> |
| count(//h2) | Количество заголовков H2 (установите фильтр извлечения на Function Value) |
| //a[contains(.,’подробнее’)] | Любая ссылка с анкорным текстом Подробнее |
| //a[starts-with(@title,’Заголовок’)] | Любую ссылку с заголовком Заголовок |
В первую очередь нам необходимо получить XPath-запрос.
Для этого на странице товара щелкаем правой кнопкой мыши по цене и выбираем пункт Inspect (Посмотреть код).
После этого мы увидим в коде сайта элемент с ценой. Далее кликаем на цену и выбираем пункт Copy > Copy Full XPath.

Рис. 5 – Пример получения XPath-запроса цены товара
Получаем код в таком формате:
/html/body/div[1]/section[2]/div/div/div[2]/div/div[2]/div[1]/div[2]/form/div[1]/p/span/bdi/span
Теперь переходим в Screaming Frog:

Рис. 6 – Переходим к извлечению данных
Вкладка Configuration > Custom > Extraction:

Рис. 7 – Окно экстракции
Вставляем сюда запрос XPath, который мы скопировали из браузера и начинаем сканирование сайта:

Рис. 8 – Результаты сканирования
В результате сканирования получаем цены товаров, которые отображаются в отдельном столбце:

Рис. 9 – Извлеченные данные можно экспортировать в отдельный файл
Теперь для выгрузки извлеченных данных выбираем заголовок столбца и нажимаем “Export”.
| Примеры XPath | Что извлекает? |
| //@href | Все ссылки |
| //a[starts-with(@href,’mailto’)]/@href | Ссылки, которые начинаются “mailto” (email адрес) |
| //img/@src | Все URL адреса источников изображений |
| //img[contains(@class,”)]/@src | Все URL адреса источников изображений с именем класса |
| //link[@rel=’alternate’] | Элементы с атрибутом rel |
| //@hreflang | Все значения hreflang |
Эти правила XPath можно использовать, когда разметка веб-сайта находится в формате микроданных. Например:
| Примеры XPath | Что извлекает? |
| //*[@itemtype]/@itemtype | Все типы микроразметки на странице |
| //*[contains(@itemtype,’BreadcrumbList’)]/*[@itemprop]/a/@href | Все ссылки на хлебные крошки |
| //*[@itemprop=’name’]/@content | Название товара |
| //*[@ itemprop = ‘description’]/@content | Описание товара |
| //*[@itemprop=’price’]/@content | Цена товара |
| //*[@itemprop=’availability’]/@href | Наличие товара |
| //*[@itemprop=’ratingCount’]/@content | Количество отзывов |
| //*[@itemprop=’ratingValue’]/@content | Средняя оценка |
Вводим 2 XPath запроса для получения количества отзывов и средней оценки:

Рис. 10 – Извлечение данных по 2-м критериям одновременно
После сканирования получаем данные со страниц, где такой вид микроразметки присутствует:

Рис. 11 – Результат
Если микроразметка выполнена с помощью JSON-LD, то нам помогут регулярные выражения, которые рассмотрим в следующей главе.
Это формула, которая помогает фильтровать нужные нам текстовые строки и получать из них необходимые данные (метасимволы, а вот термин из Википедии).
Ниже привожу синтаксис, с помощью которого мы можем самостоятельно построить регулярные выражения.
*Данное руководство не претендует на подробный гайд, а показывает лишь примеры.
| Синтаксис | Функция |
| Подстановочные знаки | |
| . | Соответствует любому 1 символу |
| * | Соответствует предыдущему символу 0 или более раз |
| ? | Соответствует предыдущему символу 0 или 1 раз |
| + | Соответствует предыдущему символу 1 или более раз |
| | | ИЛИ ЖЕ |
| Группы | |
| () | Соответствие заключенным символам в точном порядке |
| [] | Соответствие заключенным символам в любом порядке |
| – | Соответствовать любым символам в указанном диапазоне |
| Якоря | |
| ^ | Строка начинается с следующего символа |
| $ | Строка заканчивается предыдущим символом |
| Экранирование | |
| Обращайтесь к символу буквально, а не как к регулярному выражению | |
В таблицах ниже вы можете скопировать синтаксис в столбце Regex и вставить его в Screaming Frog, чтобы выполнить извлечение, описанное в столбце “Что получим?”. Измените синтаксис по своему усмотрению, чтобы настроить извлечение в соответствии с вашими потребностями.
Регулярное выражение поможет извлечь любой код, который содержится в тегах <script>. Для маркетологов это означает, что вы сможете извлекать информацию об идентификаторах отслеживания клиентов, которые используются в их аналитических или рекламных платформах.
Вот несколько примеров:
| Регулярное выражение | Что получим? |
| [“‘](UA-.*?)[“‘] | Идентификатор отслеживания Google Analytics |
| [“‘](AW-.*?)[“‘] | Идентификатор конверсии Google Рекламы и/или тег ремаркетинга |
| [“‘](GTM-.*?)[“‘] | Google Tag Manager и / или Google Optimize ID |
| fbq([“‘]init[“‘], [“‘](.*?)[“‘] | Идентификатор пикселя Facebook |
Пример проверки наличия кода GTM на всех страницах сайта:

Рис. 12 – Проверка с помощью регулярных выражений
Для получения данных о коде GTM копируем из таблицы выше регулярное выражение и вставляем в Custom Extraction, после чего начинаем сканирование сайта.
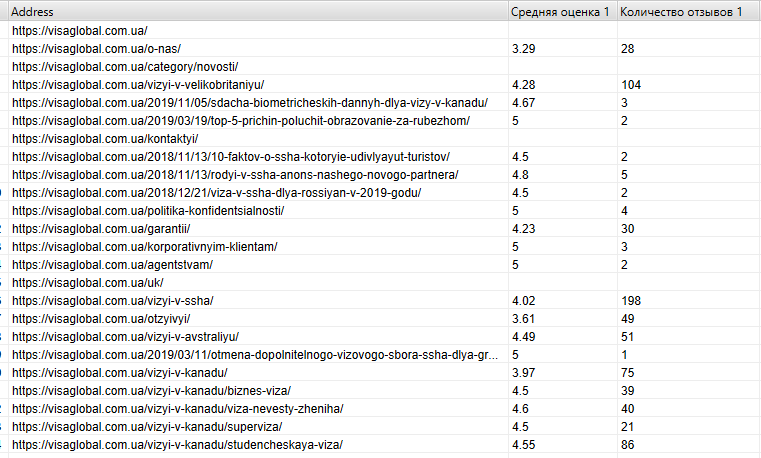
Рис. 13 – Результат сканирования
В отчете сканирования мы видим, что все страницы сайта имеют код GTM.
Ранее для парсинга всех типов микроразметки в формате JSON-LD можно было воспользоваться регулярным выражением [“‘]@type[“‘]: *[“‘](.*?)[“‘]. Оно извлекает все типы микроразметки, которые имеются на странице.
Но сейчас для парсинга микроразметки нам надо поставить соответствующую галочку в разделе Configuration > Spider > Extraction > Structured Data.
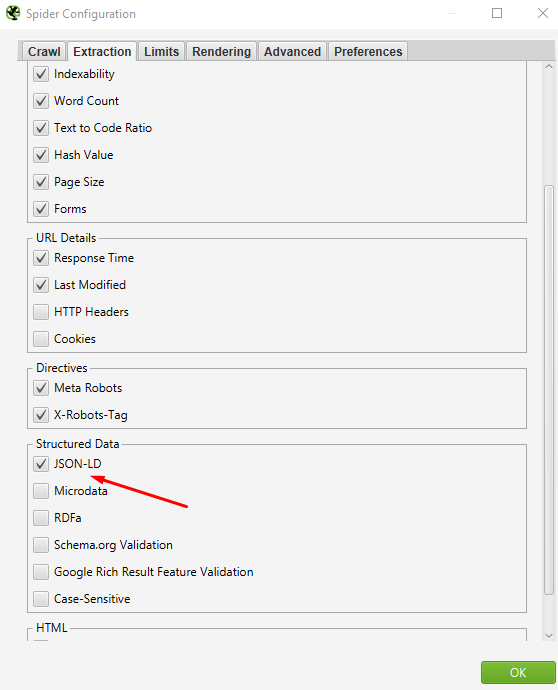
Рис. 14 – Выбор данных для извлечения
Результат такого сканирования видим ниже:
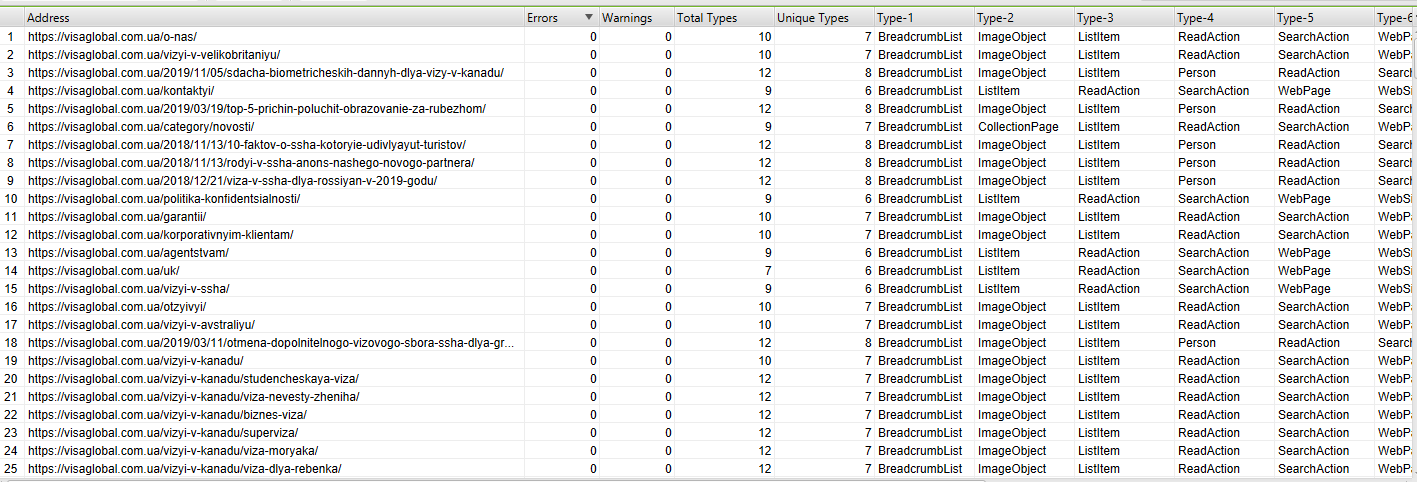
Рис. 15 – Извлечение данных по нескольким критериям
Но чтобы получить более точные данные определенного типа микроразметки, вернемся к регулярным выражениям. И для примера возьмём микроразметку Организации.
| [“‘]@type[“‘]: *[“‘]Organization[“‘].*?[“‘]name[“‘]: *[“‘](.*?)[“‘] | Извлечь название организации |
| [“‘]streetAddress[“‘]: *[“‘](.*?)[“‘] | Извлеките почтовый адрес |
| [“‘]addressLocality[“‘]: *[“‘](.*?)[“‘] | Извлечь адресную локализацию |
| [“‘]addressRegion[“‘]: *[“‘](.*?)[“‘] | Извлечь регион адреса |
| [“‘]telephone[“‘]: *[“‘](.*?)[“‘] | Извлеките номер телефона |
| [“‘]sameAs[“‘]: *[(.*?)] | Извлеките ссылки «sameAs» |
В результате сканирования по двум регулярным выражениям получили вот такие данные:
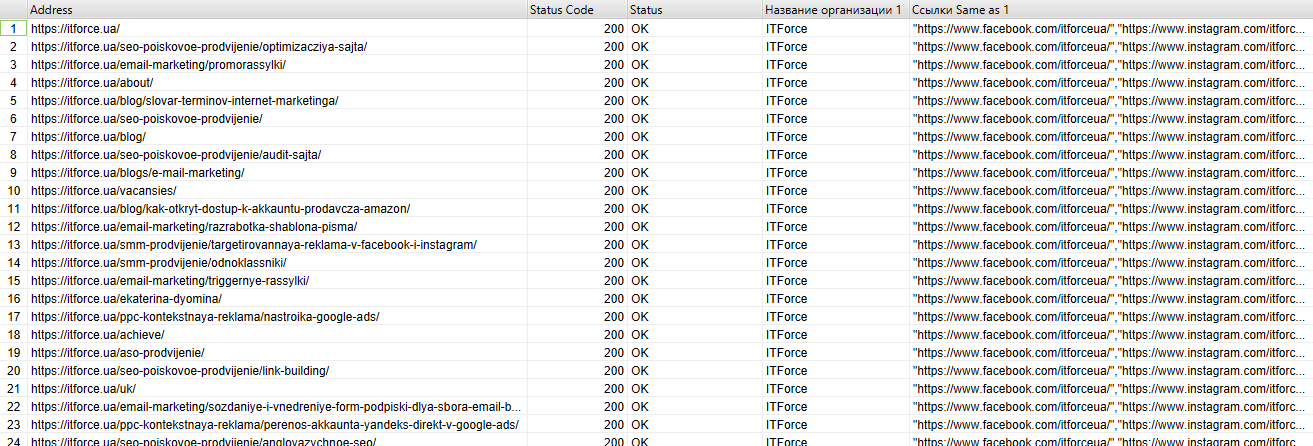
Рис. 16 – Результат сканирования
На этом все. Мы разобрали примеры на реальных проектах, из которых видно, что получить можно любые данные. Главное – знать, как.





