Одним из важных этапов при продвижении сайта является сбор семантического ядра. Семантика состоит из ключевых слов, по которым потом продвигают сайт и с которыми seo-специалист работает. К примеру, только после сбора семантического ядра и его кластеризации можно сделать правильную структуру сайта.
Выгрузить семантическое ядро можно с помощью разных сервисов, таких как serpstat или ahrefs. Но очень часто возникает проблема с тем, как же ускорить кластеризацию ключевых слов, и как правильно это сделать.
Приведу 3 пошаговых способа, как сделать кластеризацию семантического ядра.
Кластеризация семантического ядра — это распределение ключевых слов на группы, которые имеют логическую схожесть друг с другом и закрывают одинаковые потребности пользователя при поиске в поисковой системе.
С помощью кластеризации можно эффективно распределить ключевые слова по страницам или категориям, и на основе этих групп составлять стратегии продвижения.
Существует несколько вариантов кластеризации:
Поэтому, как по мне, самый удобный вариант — это смешанный. Ниже приведу несколько примеров, как это можно сделать.
Далее приведу 3 способа кластеризации семантики в таблицах Google:
Начнем.
Запросы (Queries) – это функция в Google Таблицах, позволяющая работать с данными в таблице с помощью специального языка запросов.
Язык запросов в Google Таблицах основан на SQL (Structured Query Language), который является стандартным языком для работы с базами данных. Однако он намного проще и ориентирован для работы с таблицами. Более детально можно ознакомиться в справке Google.
Для того чтобы кластеризовать семантику, я использую следующий запрос: =QUERY(диапазон ячеек; "SELECT * WHERE A CONTAINS ‘любое слово’")

Рис. 1 – Выгрузка семантического ядра
После добавления этой функции все ключевые слова, которые содержат нужное слово, будут автоматически перенесены в нужный кластер. Пример, как это сработало, приведен на скриншоте.

Рис. 2 – Добавление формулы в ячейку
Разберем мой запрос детальнее: =QUERY(‘Семантика Oribe’!A2:B862; "SELECT * WHERE A CONTAINS ‘шампун’")
‘Семантика Oribe’!A2:B862 – в диапазоне, где происходит поиск нужного слова, я написала лист, на котором нужно искать и диапазон ячеек. В моем случае это был лист Семантика Oribe. Эти значения нужно заменять.
SELECT * WHERE A CONTAINS – это выражение означает, что нужно выбрать все слова, которые содержат определенное слово. В данном случае я добавила слово "шампун" без окончания, чтобы этот запрос вытащил слова с разными вариантами окончаний.

Рис. 3 – Применение формулы к другим запросам
Преимущество этого метода в том, что вы получаете сразу готовые группы запросов, которые можно лишь немного почистить руками, и кластеры готовы.
При желании этот запрос можно доделать под разные варианты. Мне удобнее было так использовать запрос, так как я проверяю всю семантику, которую вытаскиваю по запросам, и затем чищу найденное.
Синтаксис и правила языка запросов есть в официальной справке Google.
С помощью этой формулы также можно выбрать нужные ключевые слова с определенным словом. Но придется самостоятельно копировать ключи и переносить их в кластеры.
К примеру, я взяла эту же семантику. На лист с семантикой в столбец С я добавлю формулу для поиска всех ключевых слов с вхождением слова шампунь: =FIND("шампун"; A2; 1).
Далее мне нужно эту формулу поставить в столбце С до ячейки С101, чтобы охватить все данные. Если нужно вытащить все варианты со словом шампунь, то лучше писать слово без окончания. Подробнее на скриншоте.

Рис. 4 – Кластеризация запросов с помощью формулы Найти
Для того чтобы автоматически проставить формулу по всему столбцу С до окончания заполненных ячеек:
Формула работает таким образом, что если она находит в строке ключевое слово с вхождением слова Шампунь, то она оставляет там любую цифру. Далее нужно сделать сортировку от А до Я, как показано на скриншоте. Тогда все ключевые слова со словом шампунь будут отсортированы вверх. Затем просто нужно их скопировать и почистить, и перенести на лист с кластерами.

Рис. 5 – Сортировка запросов
Результат отсортированных ключей приведен на скриншоте ниже:

Рис. 6 – Результат сортировки
Результат выходит таким же, как и при использовании функции запросов. Поэтому разницы в качестве нет. Но этот метод не переносит сразу ключевые слова, их нужно копировать и вставлять. А плюс этого метода в том, что можно разобрать все семантическое ядро и ничего не упустить, так как перенесенные ключевые слова можно удалить и кластеризовать другие. И таким образом перебрать все варианты.
Мне этот метод помог, когда мне нужно было создать как можно больше посадочных страниц для сайта.
Еще один и самый простой способ кластеризации — это просто использовать фильтры. Выделяем ячейки и создаем фильтр. Выбираем фильтр по условию.

Рис. 7 – Кластеризация с помощью фильтра
Далее выбираем Текст содержит и вставляем нужное слово для кластера. Я снова делаю кластер для шампуней от бренда. Затем нажимаем ОК и отображаются все запросы со словом шампунь.
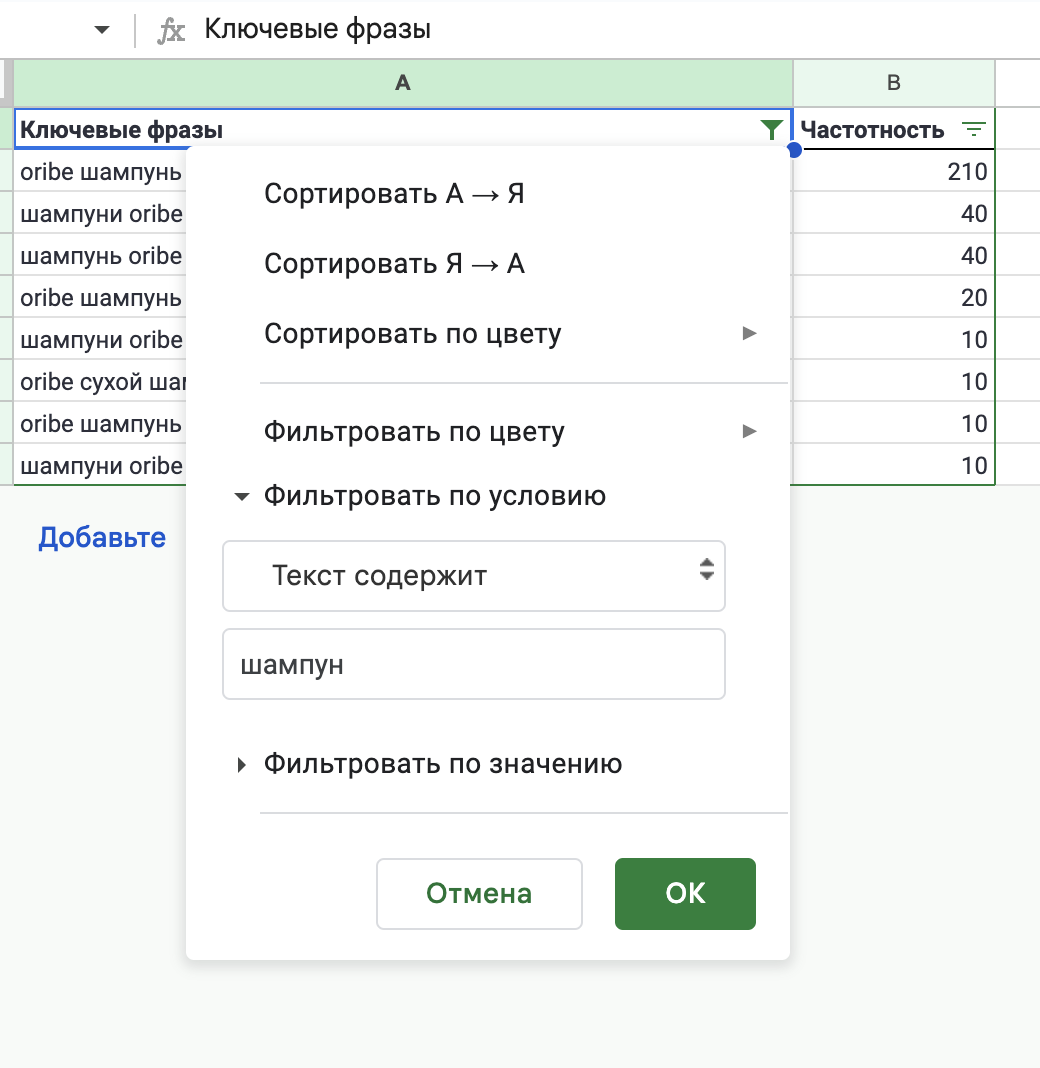
Рис. 8 – Кластеризація для запитів шампунь
Результат на скриншоте:

Рис. 9 – Результат кластеризации при помощи фильтра
Результат такой же, но этот способ также подразумевает самостоятельный перенос этих ключей. Плюс – в быстрой чистке и отсутствии пропуска ключевых слов. Самое главное, чтобы все ключевые слова были отмечены, иначе они не будут показаны.
Семантическое ядро можно кластеризовать автоматически с помощью сервисов. Существует много разных сервисов. Но в данной статье я покажу, как работает кластеризация от serpstat. Раньше мне совсем не нравилось, как работала данная кластеризация, приходилось вносить много правок вручную. Но в последнее время кластеризация именно от этого сервиса работает достаточно неплохо.
Заходим в отчет Кластеризация, Текстовая аналитика и создаем новый проект. Я решила протестировать, как эту же семантику может кластеризовать Serpstat. Заполнила поля и выбрала тип связи сильный, а тип кластеризации — жесткий. Это поможет мне сделать более точные группы запросов бренд + тип косметики.
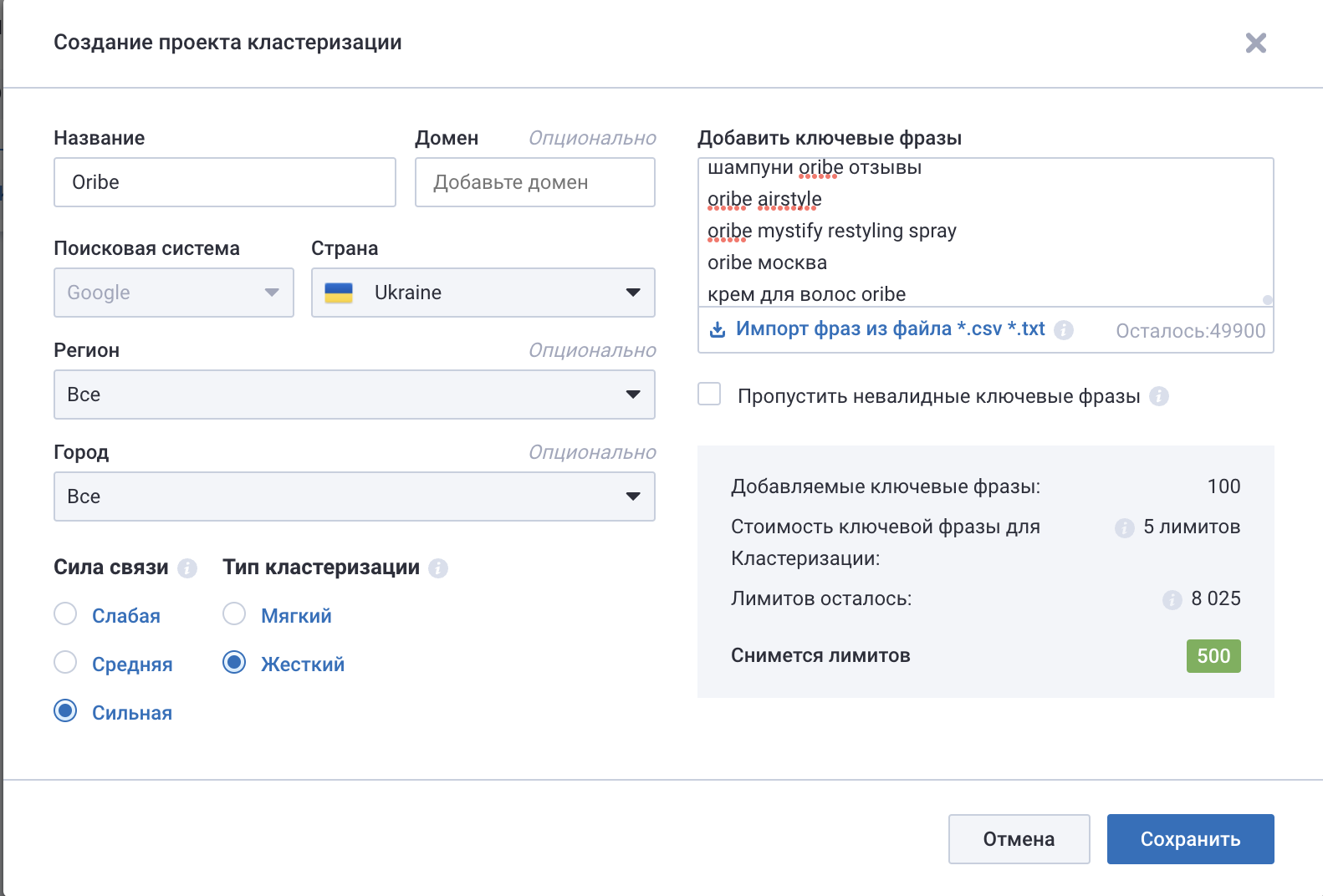
Рис. 10 – Кластеризация с помощью serpstat
Заполнив ключевые слова и нажав на Сохранить, нужно немного времени подождать, пока сервис кластеризует семантику. Теперь снова вернемся к шампуням и посмотрим, какой же кластер мы получили.

Рис. 11 – Результат кластеризации в serpstat
При жесткой связи отдельной группы для шампуней serpstat не сделал, но добавил запросы с шампунями в группу запросов oribe цена. Зато была создана группа запросов с шампунями для объема. К сожалению, из 100 ключевых слов 56 попали в группу неотсортированные, так что их все равно придется просматривать и править ручками.
После этого я тестировала мягкий тип кластеризации, но отчет вышел таким же, как и при жесткой. Таким образом, все равно нужно вручную переделывать кластеры, потому что текущие не полностью меня устраивают.
Для примеров кластеризации было выбрано нечищенное семантическое
ядро, поэтому запросы там могли попадаться вразнобой.
Все методы и способы кластеризация по-своему неплохие. Думаю, важно подбирать способ под конкретный случай. Даже если вы выбираете полностью автоматическую кластеризацию запросов, что значительно ускоряет работу, то всегда проверяйте кластеры.
Мой же любимый метод — это запросы + фильтры в google таблицах. Это помогает просматривать семантику и сразу чистить ненужные запросы.





